はじめに
OpenAIは、これまでの言語処理技術APIにChatGPTモデルとWhisperモデルを追加しました(発表記事:2023/3/1)。これにより、Whisper large-v2 音声認識モデルをAPIで使用できるようになりました。
この記事では、WhisperをWindowsコマンドプロンプトからcurlで手軽に試したいユーザ向けに考慮点とサンプルをご紹介します。また、curlに時間計測オプションを追加し、弊社がメインで使用しているWatson Speech to Text との速度比較結果もご紹介します。
準備、課題、前提
API Keys : APIの実行にはAPIキーが必要です。Open AI APIページでサインアップをしたうえで、ご自身のアカウントのAPIキーを取得してください。
APIドキュメント : Documentation Speech to text ページにAPIサンプルとオプションの説明が記載されています。しかしながらこのcurlサンプル(下記画像)は、このままではWindowsコマンドプロンプトからの実行で失敗してしまいます。これが当記事で解決したい課題点になります。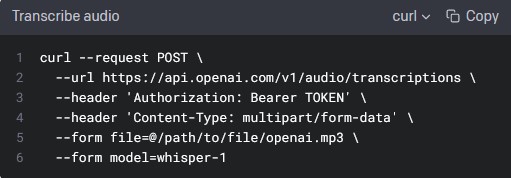
前提 : 当記事記載時点(2023/3/28)の内容です。curl 7.83.1 (Windows)
Windows curl でWhisper APIを実行する
上記サンプルで失敗する理由は、Windowsコマンドプロンプトの (1)文字列を囲む引用はダブルクォーテーション (2)バックスラッシュ(\)で複数行をつなげられない という制約があるからです。
ですから、curlサンプルをコピーしたら、メモ帳などエディターに貼り少し修正をしてあげましょう(以下手順)
シングルクォート : シングルコーテーションをダブルコーテーションに変更します。エディターの置換操作を使うと便利です。
バックスラッシュor¥マークと複数行対応 : 複数行をつなげる役割のバックスラッシュ("\", "¥")を削除すると共に複数行になっているコマンドを一行にします。(キャレット("^")で置き換えることもできますがこの後の操作のために繋げておきましょう)
APIキー : コマンド中の”TOKEN”を先に取得したAPIキーで置き換えます。
音声ファイル名 : "file=@~"の記述のアットマーク以降をファイル名(カレントディレクトリに無い場合は¥文字を使ったフルパス)で置き換えます。
以下、コマンドと実行結果のサンプルです(注意:APIキーとファイル名は架空のものです)
C:¥>curl --request POST --url https://api.openai.com/v1/audio/transcriptions --header "Authorization: Bearer ab-CdEfGhIjKlMnOpQrStUvWxYz0" --header "Content-Type: multipart/form-data" --form file=@\Users\Admin\Documents\ABC.mp3 --form model=whisper-1
**以下実行結果サンプル**
{"text":"こんにちは"}
以上の作業でWhisper APIコールで音声ファイルからの文字起こしができました、お疲れさまでした。
個人的には、言語指定をしなくても日本語音声が日本語で書き起こされることに驚きました。
(応用)結果表示を整える
結果表示はJSON形式です。以下オプションを追加することで結果テキストのみを取り出すことができます。
--form response_format=text
curlの出力オプションを使って実行時間を表示します。
--write-out Time:%{time_total}
(参考)実行時間の計測結果
以下は、59秒のmp3音声ファイルをcurl経由で書き起こすテストケースの所要時間です(3回平均)
・Whisper(whisper-1): 5.58619 秒
・Watson Speech to Text(ja-JP_Multimedia): 20.63841 秒
単純に比較できない部分もありますが、処理速度も驚異的な性能であることが確認できました。
認識結果も期待以上でした。
まとめ
認識精度に定評があるWhisperを手持ちの音声ファイルで手軽に試すことができました。弊社はこのメリットを活かせるソリューションの検討を進めてまいります。
※当記事はChatGPTの生成文を利用/参照しています。
